The Illustrated Guide to a PhD is the latest article to come across my social feed whose intent is to pour cold water on the idea of studying for a PhD. It's reproduced in Business Insider, although the original can be found at Prof Matt Might's personal blog, where he posts about CS research (static analysis) at the University of Utah. Have a look at its characterisation of a PhD - it could be summarised as "why bother, you're just an insignificant pimple on the ignorance of humanity". The relevant diagram is included below, and shows the different levels of education (school, college, undergraduate, masters, PhD) as different coloured areas that might be all-round education that covers all topics (compulsory education) or niche and deep (higher education). A PhD touches and extends the boundaries of human knowledge (the black outer circle) in one very specific area, and so it appears as a small pimple that pushes the boundary slightly outwards.
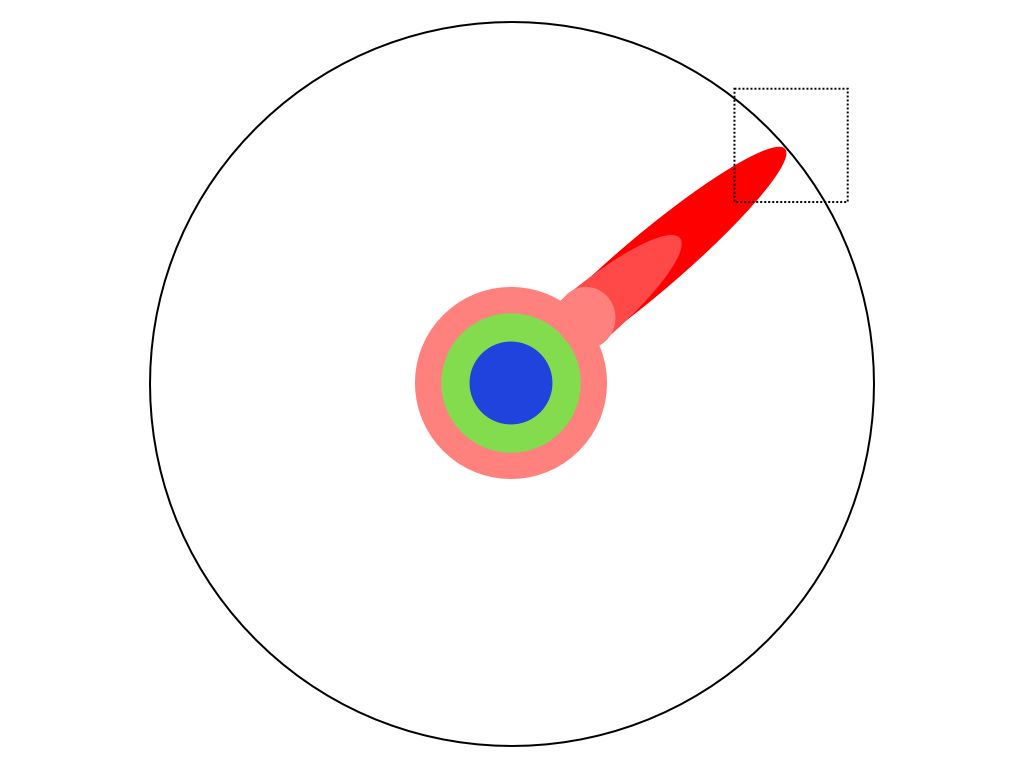
To try to get another perspective on this, I did a few rough calculations (not so much data science as back-of-the-envelope science). In fact, the circles and pimples radically underestimate the situation - in order to represent the contribution that a single PhD student makes as a single pixel, the circle would need to be the about the size of a swimming pool. In other words the situation is worse (much worse) than the picture provided, but that's not because there's anything wrong with PhD research. It's because the world is so much bigger and more complex than we imagine; there is SO MUCH knowledge out there, and there are SO MANY researchers trying to extend the boundaries of human understanding, human craft and human ingenuity. Each PhD candidate may produce a tiny pimple of knowledge, but there are more than half a million of them across the world and but you know what they say - a million contributions here and a million contributions there and pretty soon you're talking real progress.
The aggregate achievement of higher degrees is significant, but what is the personal outcome? What is the significance of one pimple? The PhD doesn't just represent the attainment of a specific piece of knowledge, it represents the acquisition of specific expertise and human capability. It attests to a human being who knows how to address problems, how to propose novel solutions rationally synthesised from a broad base of evidence and experience. A PhD isn't someone stuck with niche and irrelevant knowledge, its someone who can apply crucial higher order skills and expertise for the economy and for society.
So don't lose heart about your PhD just because the world, the economy and society provide enormous challenges that can dwarf us all, remember that the point of a PhD is to transform YOU into part of the solution.
TL;DR
Here's my calculations about Matt's diagrams.
The width of the "bachelors speciality" is 57 pixels of a total 597 pixels salmon circumference, ie some 9.5% of all the subjects of human knowledge. In fact the number of separate undergraduate degree courses obtainable from my University is 331. Of course, many of these courses will overlap (let's guess that 1/3 of them are properly unique), on the other hand there are many areas of knowledge that we don't provide courses in (let's guess we cater for about 1/3 of all the subjects). Those two factors might tend to balance out, so I'll stick with 300 as the canonical number of undergraduate degree subjects. In other words, one person's undergraduate knowledge will represent a 0.33% covereage of all potential subject areas, and the UG pimple is 30 times too wide.
Lets look at this from the point of view of how many PhD students there might be out there: in the UK there are around 67,000 postgraduate research students in 2012/3 according to HESA statistics (536440 postgraduate students, of which around 1/8 are on PhD courses rather than postgraduate taught courses). Even if we scale this up by just a factor of 10 to represent the global population of PhD students, this is 2/3 of a million PhD students currently pressing forward in their own unique areas with their own unique pixels. That would require the circle to be 240 times larger, as big as a 25m swimming pool!

